My CSC master’s project was transparent failover for Linux server processes. The goal was to keep two copies of a server running on separate machines, synchronized closely enough that one could take over immediately if the other failed, without dropping TCP connections or losing any application state.
Publications
Goal
Network servers need high availability despite hardware failures and maintenance, but most existing servers have no way to hand control to a backup while preserving both application state and network state.
This project was to support failover for an existing server without modifying the server itself. A master overseer would monitor the primary server and trap its system calls and network access. A backup overseer would verify that the backup maintained the same state as the master, and if communication with the master was lost, the backup would assume the master’s network state and continue service.
Implementation
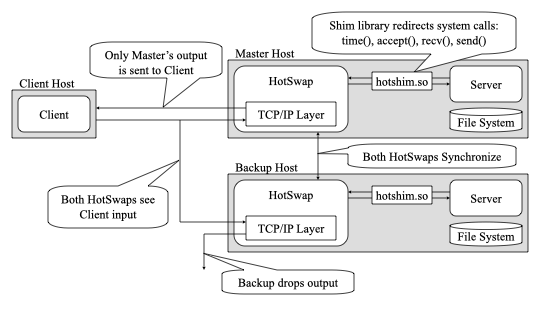
The core idea was to provide transparent failover for existing UNIX servers without rewriting them. A master server and a backup server would start from the same initial state, use identical copies of the files they depend on, and then run in parallel. If either machine failed, the other should be able to take over without breaking live client TCP connections.
The hard part was not just restarting a failed service. The backup had to match the master’s internal memory state, file descriptor state, encryption state, and TCP connection state. If any of those diverged, the client connection would break or data would be lost.
I was aiming this at ordinary software that did not already have high availability support built in. The examples I had in mind were servers like Apache, PostgreSQL, MySQL, and other long-running UNIX services where a failure normally means reconnecting and reconstructing application state.
How It Worked
How do you make the backup process consume and produce exactly the same stream of events as the master? My solution was to control and synchronize the system call inputs to all processes.
- Run identical server processes on both machines.
- Intercept system calls so both copies see the same inputs from system calls like
time(),getpid(),open(),read(),send(), andrecv(). - Keep the TCP state synchronized so the backup can take over the master’s sequence numbers, acknowledgements, addresses, and connection buffers.
- Compare replicated state as the processes run, so the backup is always ready to stop discarding its output and become the live server.
That pushed the design toward a shim layer for trapping system calls plus a custom approach for synchronizing TCP/IP state.
I demonstrated the idea with an encrypted HTTP server running in sync on two Linux boxes. I demontrated that one Linux box could be killed and the backup would continue mid stream preserving application state, encryption state, and TCP.